Abstract

Estimating human and camera trajectories with accurate scale in the world coordinate system from a monocular video is a highly desirable yet challenging and ill-posed problem. In this study, we aim to recover expressive parametric human models (i.e., SMPL-X) and corresponding camera poses jointly, by leveraging the synergy between three critical players: the world, the human, and the camera. Our approach is founded on two key observations. Firstly, camera-frame SMPL-X estimation methods readily recover absolute human depth. Secondly, human motions inherently provide absolute spatial cues. By integrating these insights, we introduce a novel framework, referred to as WHAC, to facilitate world-grounded expressive human pose and shape estimation (EHPS) alongside camera pose estimation, without relying on traditional optimization techniques. Additionally, we present a new synthetic dataset, WHAC-A-Mole, which includes accurately annotated humans and cameras, and features diverse interactive human motions as well as realistic camera trajectories. Extensive experiments on both standard and newly established benchmarks highlight the superiority and efficacy of our framework. We will make the code and dataset publicly available.



(Updated: 2024/09/26)
Images: 16GB needed for each file.
1. DuetDance-20240218-000.tar
2. DuetDance-20240218-001.tar
3. DuetDance-20240218-002.tar
ImagesAnnotations: 400MB needed for Testset and 2GB for each Trainset.
1. synbody_whac_DuetDance-20240218_240426_200_test_camera-000_0.01.npz
2. synbody_whac_DuetDance_240222_200_train_0.npz
3. synbody_whac_DuetDance_240222_200_train_1.npz
Annotations
Visualization of estimated human poses and trajectories of in-the-wild videos in the world coordinate.
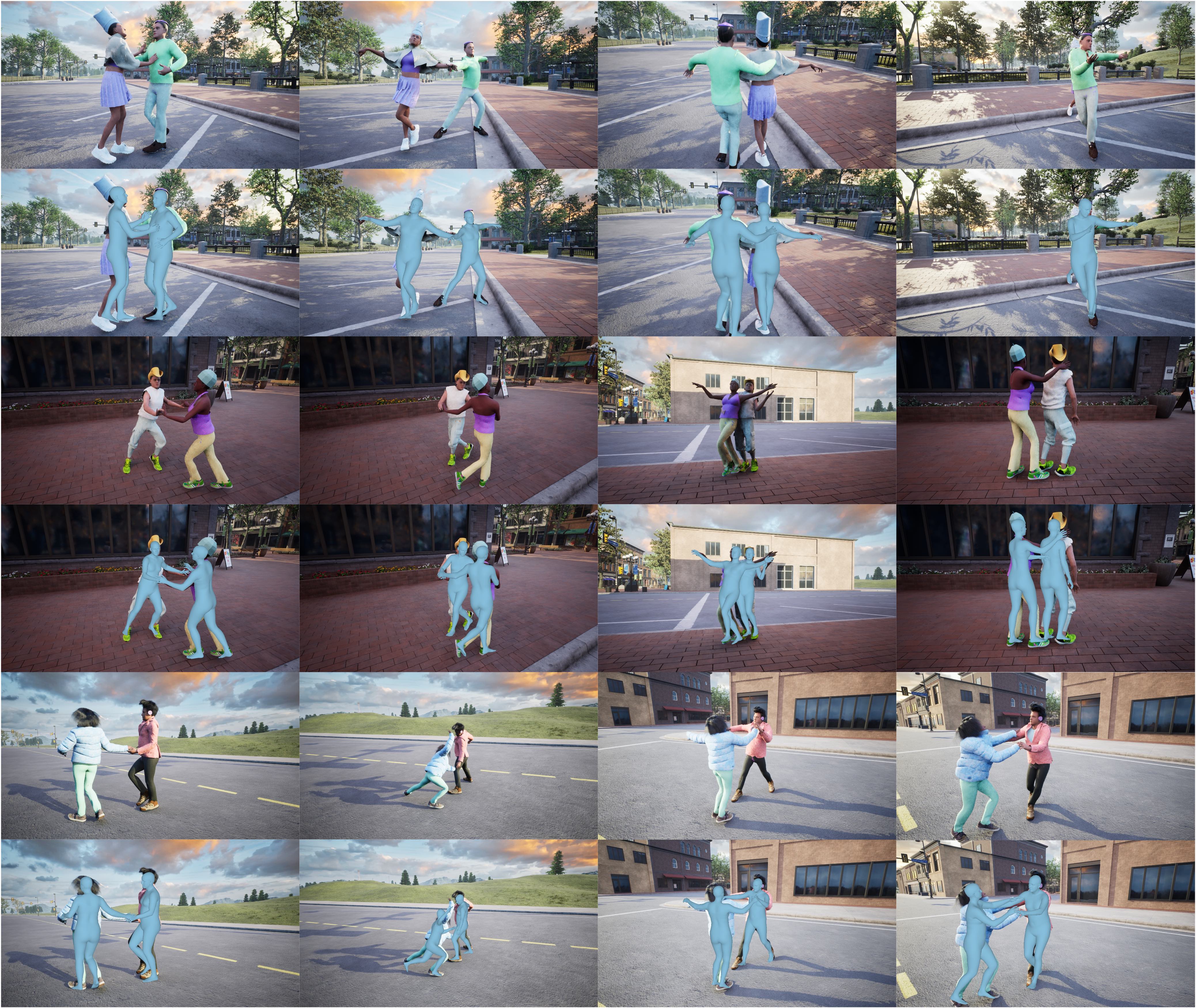
Visualization of estimated human poses on the WHAC-A-Mole dataset in the camera coordinate.